vLLMs
5Ws
Paged Attention
Problem: LLM performance is bottlenecked by memory, KV tensor cache is large, consumes 1.7GB for a single sequence and is dynamic, KV cache size depends on sequence length which is highly variable unpredictable. Existing systems waste 60-80% of memory due to fragmentation and over-reservation.
vLLM delivers up to 24x higher throughput than hugging face transformers. without model architecture changes. the idea is inspired by operating systems. we can store continuous keys and values in non-contiguous memory space (preventing fragmentation). paged attention partitions KV cache of each sequence into blocks.
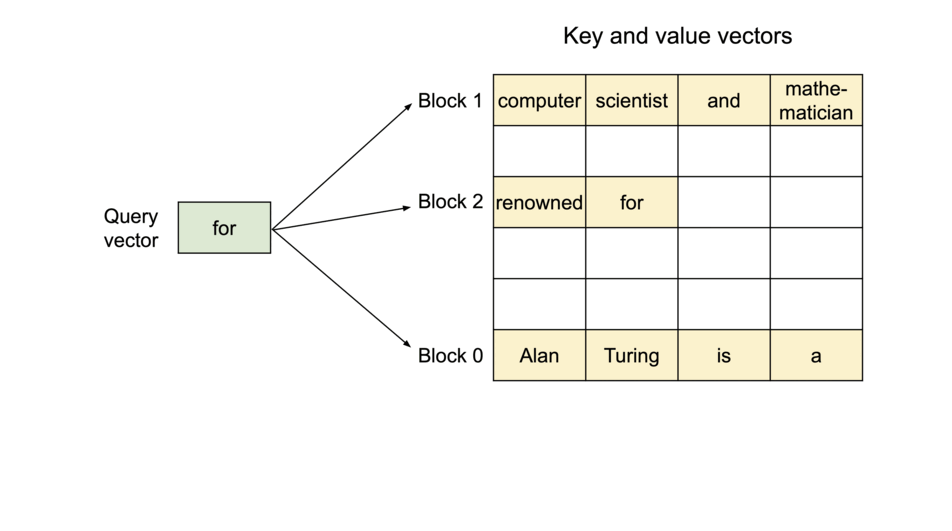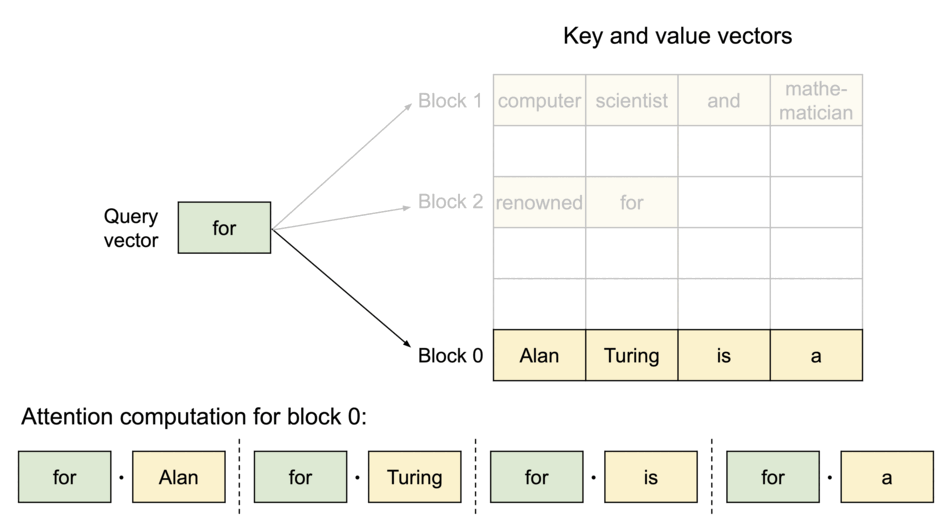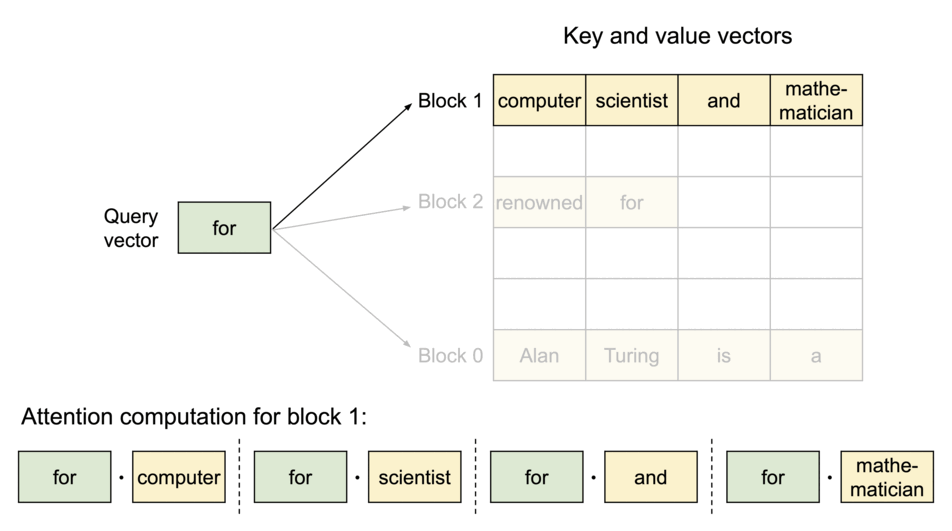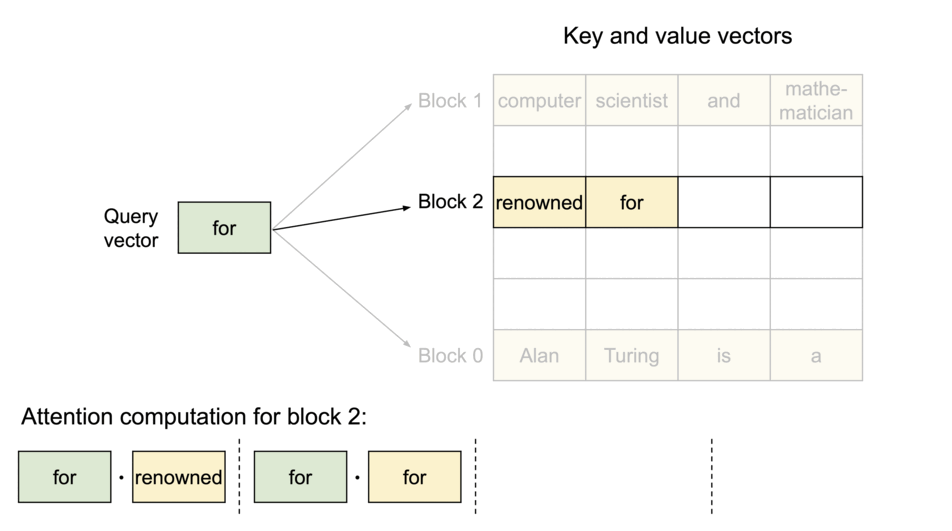
because the blocks do not need to be in contiguous space, we can arrange the pages accordingly. Lets rename blocks and pages, tokens as bytes and sequences as processes.
since we add each token’s KV value into blocks of x size, we can allocate more memory at runtime
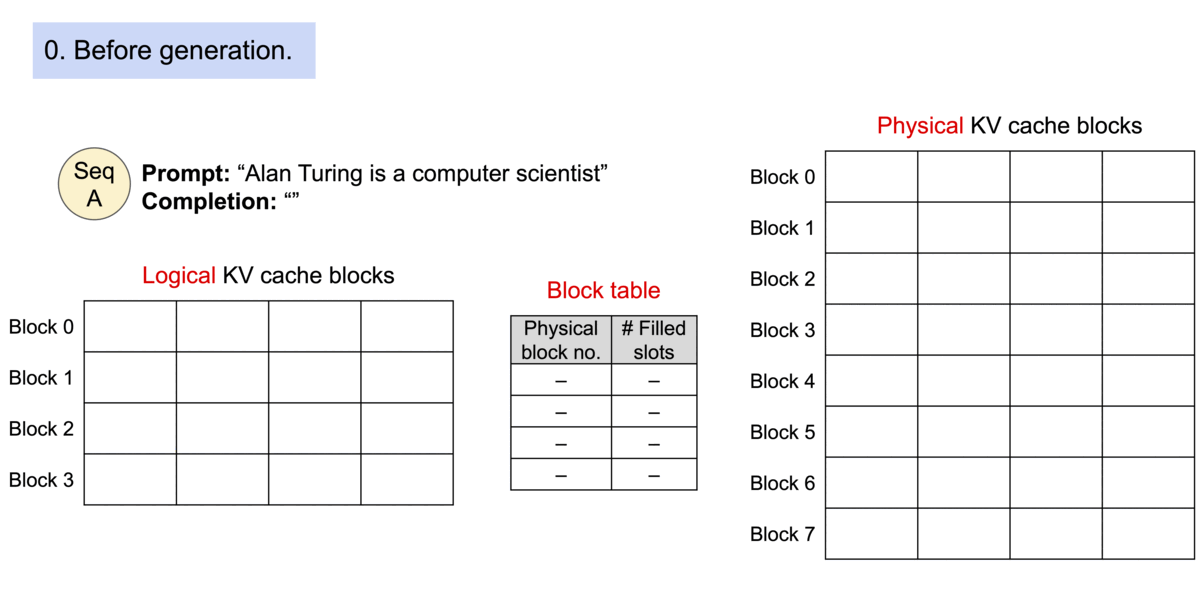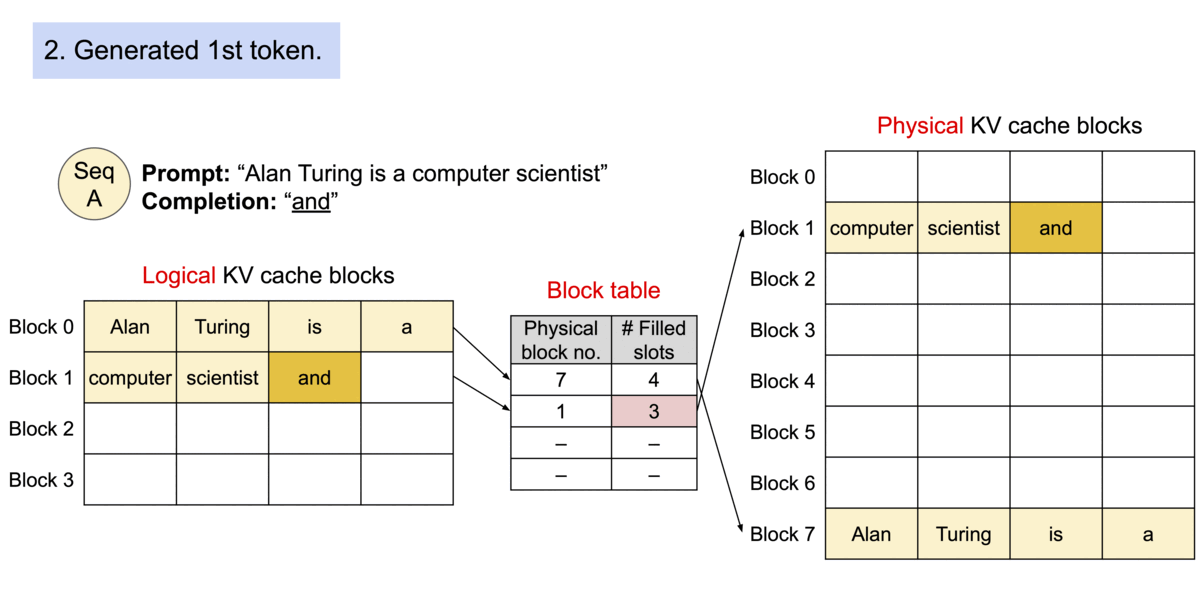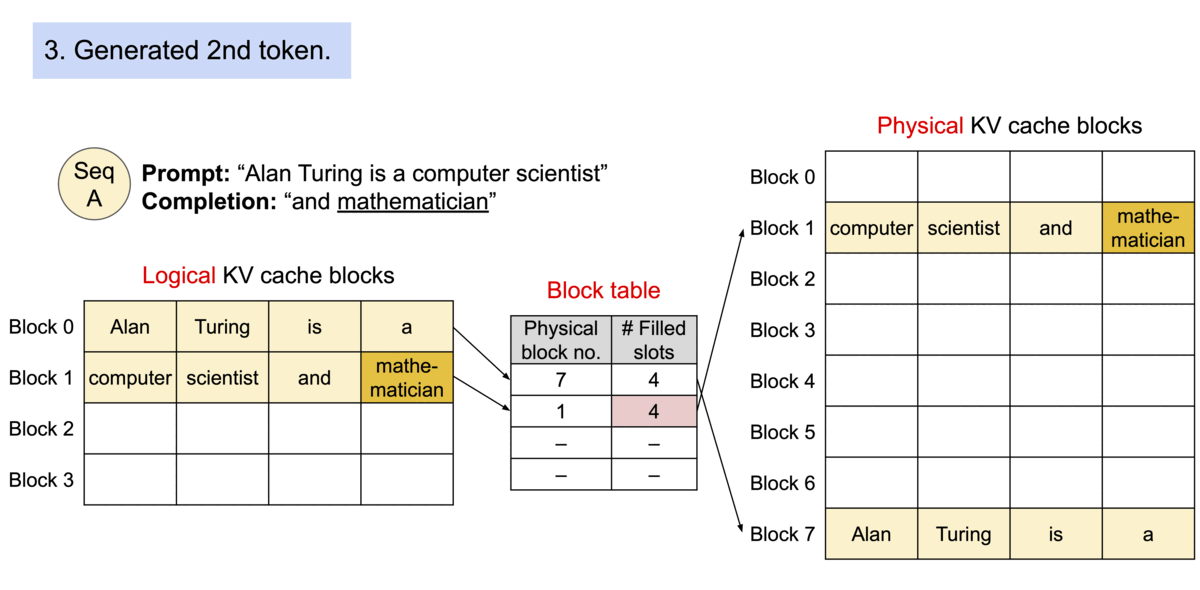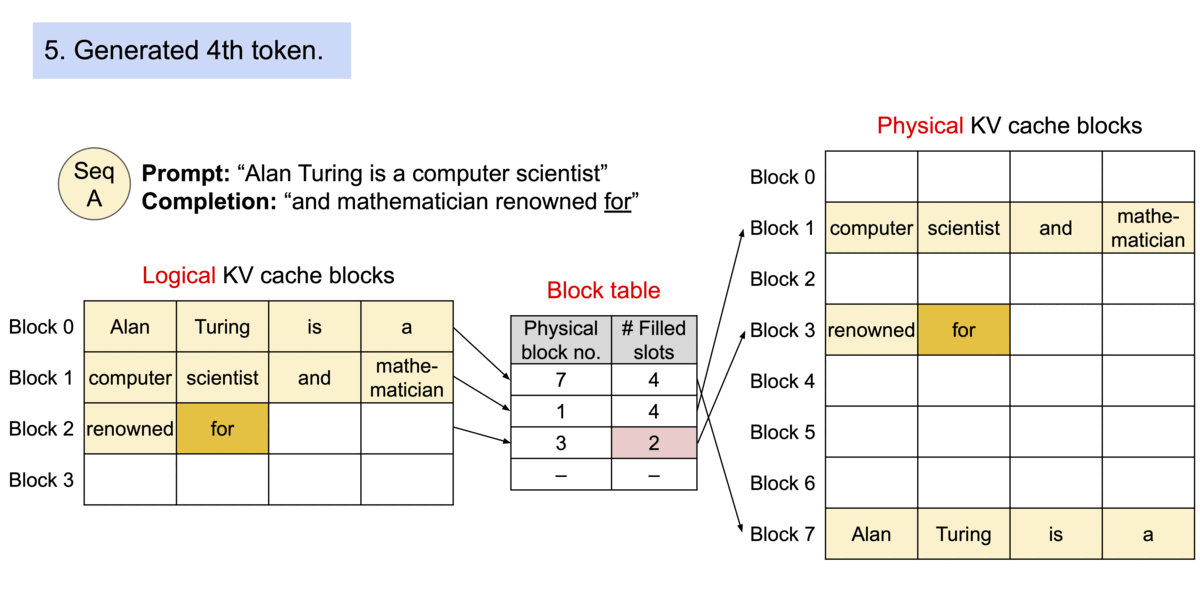
another advantage is: efficient memory sharing, many processes (sequences) can share the same physical blocks from their own logical blocks.
pagedAttention also reduces memory overhead of sampling algorithms cutting thier memory usage by 55%.
Whats copy on write mechanism
each physical block has a reference count showing how many logical blocks are pointing to it.
cow mechanism saves memory via shared prefixes, prompt parts.
LLM engine
components:
KV cache manager maintains a free_block_queue a pool of available KV cache blocks, during paged attention these blocks serve as indexing structure that map tokens to relevent KV cache blocks.
Initialization process
during model execution worker obj is created and three procedures are executed, these same procedures run independently on each worker process across different GPUs
synchronous Generate function
Step function
each step function has three stages
Scheduler
two main types of workloads an inference engine handles
V0 cant decode or prefill at the same time, but V1 engine can do
wfewf dsvsd